Level Based Foraging
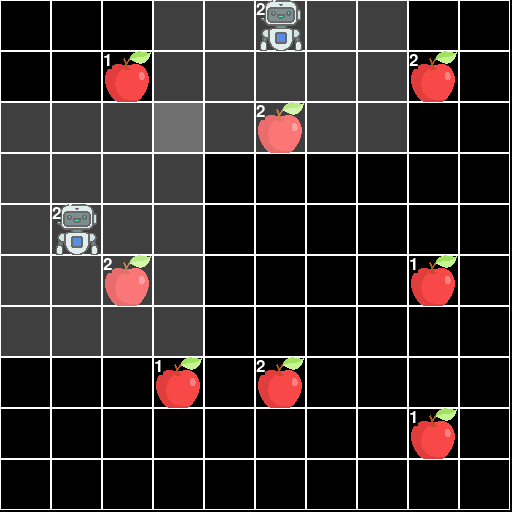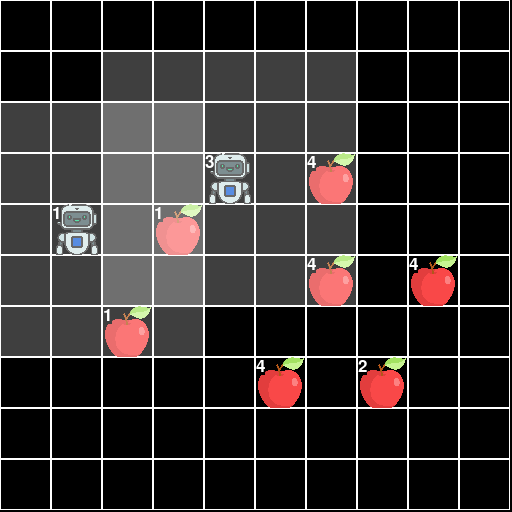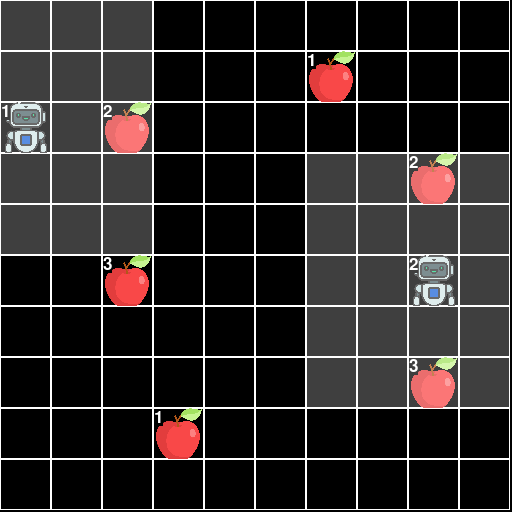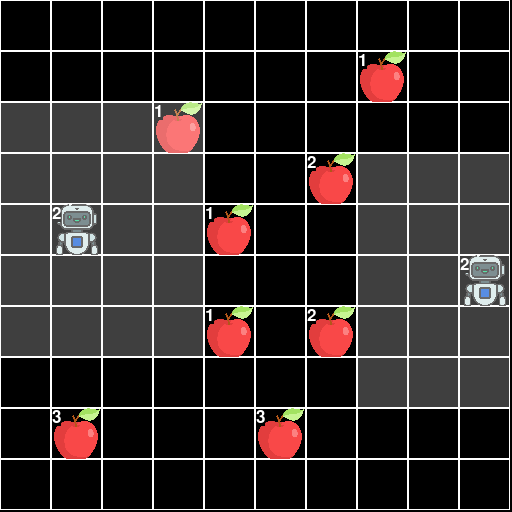
This environment is part of the Grid World environments. Please read that page first for general information.
Possible Agents |
(‘0’, ‘1’) |
Action Spaces |
{‘0’: Discrete(6), ‘1’: Discrete(6)} |
Observation Spaces |
{‘0’: Tuple(Discrete(11, start=-1), Discrete(11, start=-1), Discrete(4), Discrete(11, start=-1), Discrete(11, start=-1), Discrete(4), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7)), ‘1’: Tuple(Discrete(11, start=-1), Discrete(11, start=-1), Discrete(4), Discrete(11, start=-1), Discrete(11, start=-1), Discrete(4), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7), Discrete(12, start=-1), Discrete(12, start=-1), Discrete(7))} |
Symmetric |
True |
Import |
|
The Level-Based Foraging Environment.
This implementation is based on the original implementation of Level-Based Foraging environment: https://github.com/semitable/lb-foraging. We modify their original version to support access to the environments dynamic’s model as well as adding more control over the layout of food in the world.
The Level-Based Foraging is a 2D grid-world involving multiple agents each of which is trying to collect as much food as possible. A finite amount of food is spread throughout the world which the agents can collect. The key interesting feature is that both the agents and the food have levels and a piece of food can only be picked up if the sum of the levels of all the agents trying to pick up the food is greater than the foods level. This incentivizes cooperation between agents.
The problem can be set in two-modes: cooperative and mixed. In cooperative mode
agents share rewards and so are fully incentivized to work together. While in mixed
mode agents rewards are given individually so they are incentivized to cooperate to
collect food with higher levels, but also incentivized to act greedily to collect
lower level food by themselves, creating an interesting social-dilemma.
Agents
Between 2 and 4, with all agents active throughout every episode.
State Space
The state of the environment is defined by a (x, y, level) triplet for each agent
and food object in the environment. The (x, y) components define the position of
the agent or food, starting from the bottom left square. The level component is
the level of the agent or food.
Action Space
Each agent has six possible discrete actions: NOOP=0, NORTH=1, SOUTH=2,
WEST=3, EAST=4, and LOAD=5. The NORTH, SOUTH, WEST, EAST actions move the
agent in the given direction, while the LOAD action attempts to pickup any adjacent
food. The NOOP action does nothing.
Observation Space
Each agent observes the (x, y, level) of food and other agent within their field
of vision, which is sight distance away from the agent in all directions.
There are three observation modes:
grid
The agent receives three 2D layers of size (
1+2*sight,1+2*sight). Each cell in each layer corresponds to a specific (x, y) coordinate relative to the observing agent. The layers are:agent level
food level
whether cell is free or blocked (e.g. out of bounds)
vector
A vector of
(x, y, level)triplets for each food and agent in the environment. If a given food or agent is not within the observing agent’s field of vision triplets have a value of(-1, -1, 0). The size of the vector is(num_agents + max_food) * 3, with the firstmax_foodtriplets being for the food, themax_food+1triplet being for the observing agent and the remainingnum_agents-1triplets for the other agents. The ordering of the triplets for the other agents is consistent, while the food obs triplets can change based on how many are visible and their relative coordinates to the observing agent.
tuple
This is the same as the vector observation except observations are Python tuples of integers instead of numpy arrays of floats.
Rewards
Agents receive a reward whenever they successfully pick-up food. The reward received by each agent depends on the food’s level and how many agents picked up the food and their levels. In cooperative mode all agents receive the same reward. The reward per food item is set so that the max sum of rewards for an episode is 1.0 (minimum is 0.0).
Dynamics
Actions are deterministic with each agent’s movement action resulting in them moving
1 cell in the given direction so long as that cell is not occupied or out-of-bounds.
The LOAD action will only succeed if the agent is adjacent to a food object and
the agents level is higher than the food level, or other agents are attempting to
load the food at the same time, and the sum of the all loading agent’s levels is
greater than the food’s level. If a food is successfully loaded then it is removed
from the map.
Starting State
The initial state depends on if the environment is using a static_layout or not.
When using a static layout each agent will start from the same location, in one of the corners or half-way along one of the grid’s edges, each episodes and the food will be in the same positions. The level of each agent and food will be selected randomly. The static layout is useful when using a planner since the number of possible initial states is significantly reduced.
When not using the static layout, agent starting and food locations are selected randomly from all possible positions, and the agent and food levels are also selected randomly.
Episodes End
Episodes end when all food has been collected. By default a max_episode_steps is
also set for each Driving environment. The default value is 50 steps, but this may
need to be adjusted when using larger grids (this can be done by manually specifying
a value for max_episode_steps when creating the environment with posggym.make).
Arguments
num_agents- the number of agents in the environment (default =2).max_agent_level- the maximum level of an agent (default =3).size- the width and height of the square grid world (default =10).max_food- the maximum number of food that will appear in an episode (default =8).sight- the local observation dimensions, specifying how many cells in each direction the agent observes (default =2, resulting in the agent observing a 5x5 area)force_coop- whether all agents share all rewards (i.e. fully cooperative mode) (default = “False”).static_layout- whether to use a static food layout. If true then the same number of food will always appear each episode and always in the same locations. The level of the food will be random each episode. If false, food location and levels is random each episode (default = ‘False`)observation_mode- the observation mode to use out ofgrid,vector, ortuple(default=tuple)
Version History
v3: cleaned up version ofv2with some minor changes, mostly removing unused parameters:removed
penaltyoption for penalizing failed load actionsremoved
normalize_rewardoption (always normalize rewards now)changed
field_sizeparameter tosizeand restricted field to be a square (field_size/sizeis now a single int)
v2: Version adapted from https://github.com/semitable/lb-foraging
References
Stefano V. Albrecht and Subramanian Ramamoorthy. 2013. A Game-Theoretic Model and Best-Response Learning Method for Ad Hoc Coordination in Multia-gent Systems. In Proceedings of the 2013 International Conference on Autonomous Agents and Multi-Agent Systems. 1155–1156.
S. V. Albrecht and Peter Stone. 2017. Reasoning about Hypothetical Agent Behaviours and Their Parameters. In 16th International Conference on Autonomous Agents and Multiagent Systems 2017. International Foundation for Autonomous Agents and Multiagent Systems, 547–555
Filippos Christianos, Lukas Schäfer, and Stefano Albrecht. 2020. Shared Experience Actor-Critic for Multi-Agent Reinforcement Learning. Advances in Neural Information Processing Systems 33 (2020), 10707–10717
Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, and Stefano V. Albrecht. 2021. Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks. In Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)