Driving
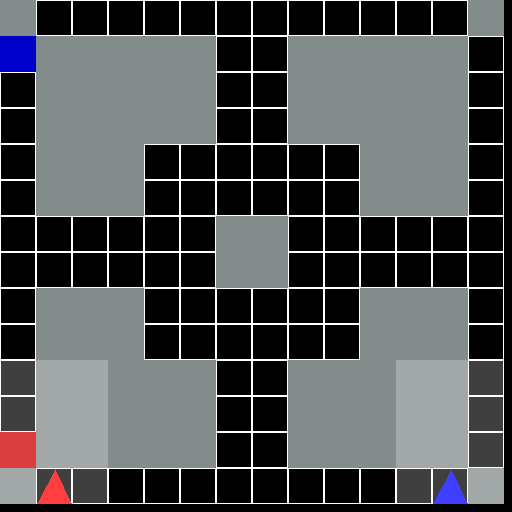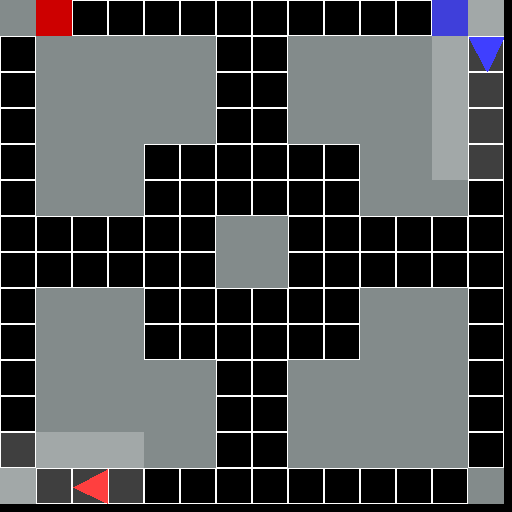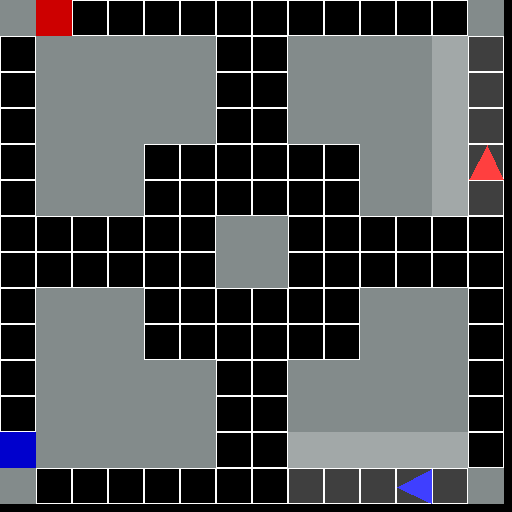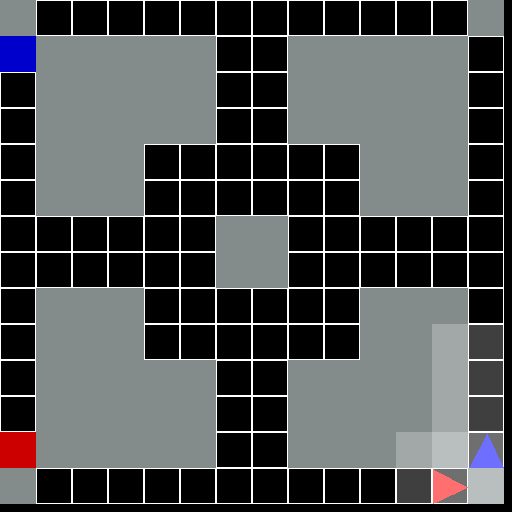
This environment is part of the Grid World environments. Please read that page first for general information.
Possible Agents |
(‘0’, ‘1’) |
Action Spaces |
{‘0’: Discrete(5), ‘1’: Discrete(5)} |
Observation Spaces |
{‘0’: Tuple(Tuple(Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4)), Discrete(4), Tuple(Discrete(14), Discrete(14)), Tuple(Discrete(14), Discrete(14)), Discrete(2), Discrete(2)), ‘1’: Tuple(Tuple(Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4), Discrete(4)), Discrete(4), Tuple(Discrete(14), Discrete(14)), Tuple(Discrete(14), Discrete(14)), Discrete(2), Discrete(2))} |
Symmetric |
True |
Import |
|
The Driving Grid World Environment.
A general-sum 2D grid world problem involving multiple agents. Each agent controls a vehicle and is tasked with driving the vehicle from it’s start location to a destination location while avoiding crashing into other vehicles.
This environment requires each agent to navigate in the world while also taking care to avoid crashing into other agents. The dynamics and observations of the environment are such that avoiding collisions requires some planning in order for the vehicle to brake in time or maintain a good speed. Depending on the grid layout, the environment will require agents to reason about and possibly coordinate with the other vehicles.
Possible Agents
The environment supports two or more agents, depending on the grid. It is possible for some agents to finish the episode before other agents by either crashing or reaching their destination, and so not all agents are guaranteed to be active at the same time. All agents will be active at the start of the episode however.
State Space
Each state is made up of the state of each vehicle, which in turn is defined by:
the
(x, y)coordinates (x=column, y=row, with origin at the top-left square of the grid) of the vehicle,the direction the vehicle is facing
NORTH=0,EAST=1,SOUTH=2,WEST=3,the speed of the vehicle:
REVERSE=0,STOPPED=1,FORWARD_SLOW=2,FORWARD_FAST=2,the
(x, y)coordinate of the vehicles destinationwhether the vehicle has reached it’s destination or not:
1or0whether the vehicle has crashed or not:
1or0the minimum distance to the destination achieved by the vehicle in the current episode.
the initial distance of the vehicle to the destination at the start of the episode.
Action Space
Each agent has 5 actions: DO_NOTHING=0, ACCELERATE=1, DECELERATE=2,
TURN_RIGHT=3, TURN_LEFT=4
Observation Space
Each agent observes the cells in their local area, as well as their current speed,
current location, their destination location, whether they’ve reached their
destination, and whether they’ve crashed. The size of the local area observed is
controlled by the obs_dims parameter (default = (3, 1, 1), 3 cells in front,
one cell behind, and 1 cell each side, giving a observation size of 5x3).For each
cell in the observed area the agent observes whether the cell contains a
VEHICLE=0, WALL=1, EMPTY=2, or it’s DESTINATION=3.
All together each agent’s observation is tuple of the form:
((local obs), speed, coord, destination coord, destination reached, crashed)
Rewards
If an agent crashes into a vehicle (or is crashed into) they receive a penalty of
-1.0. A reward of 0.5 is given if the agent reaches it’s destination.
Additionally, agents receive a small reward each step they makes progress towards
their destination (i.e. the agent reduces it’s minimum distance achieved to the
destination for the episode). The total amount of reward and agent receives for
making progress is 0.5, and is distributed evenly across all steps the agent
makes progress. This means if the agent reaches their destination they will receive
a total reward of 1.0 (0.5 for reaching their destination, and 0.5 for
progress).
Dynamics
Actions are deterministic and movement is determined by direction the vehicle is facing and it’s speed:
Speed=0 (REVERSE) - vehicle moves one cell in the opposite direction to which it is facing (vehicles cannot turn while in reverse)
Speed=1 (STOPPED) - vehicle remains in same cell
Speed=2 (FORWARD_SLOW) - vehicle move one cell in facing direction
Speed=3 (FORWARD_FAST) - vehicle moves two cells in facing direction
Accelerating increases speed by 1, while deceleration decreased speed by 1. If the vehicle will hit a wall or another vehicle when moving from one cell to another then it remains in it’s current cell and it’s speed is reduced to 1 (STOPPED).
Starting State
Each agent is randomly assigned to one of the possible starting locations on the grid and one of the possible destination locations, with no two agents starting in the same location or having the same destination location. The possible start and destination locations are determined by the grid layout being used.
Episodes End
Episodes end when all agents have either reached their destination or crashed. By
default a max_episode_steps is also set for each Driving environment. The default
value is 50 steps, but this may need to be adjusted when using larger grids (this
can be done by manually specifying a value for max_episode_steps when creating the
environment with posggym.make).
Arguments
grid- the grid layout to use. This can either be a string specifying one of the supported grids, or a custom :class:DrivingGridobject (default ="14x14RoundAbout").num_agents- the number of agents in the environment (default =2).obs_dim- the local observation dimensions, specifying how many cells in front, behind, and to each side the agent observes (default =(3, 1, 1), resulting in the agent observing a 5x3 area: 3 in front, 1 behind, 1 to each side.)
Available variants
The Driving environment comes with a number of pre-built grid layouts which can be
passed as an argument to posggym.make, to create different grids:
Grid name |
Max number of agents |
Grid size |
|---|---|---|
|
2 |
3x3 |
|
4 |
6x6 |
|
4 |
7x7 |
|
6 |
7x7 |
|
4 |
7x7 |
|
4 |
14x14 |
|
8 |
14x14 |
|
4 |
14x14 |
For example to use the Driving environment with the 7x7RoundAbout grid and 2
agents, you would use:
import posggym
env = posggym.make('Driving-v1', grid="7x7RoundAbout", num_agents=2)
Version History
v1: Major update:Added agent’s current location to observation space (to allow for the creation of heuristic policies for the environment and mimics GPS),
made it so vehicles speed is reduced to 0 if they crash or hit a wall (instead of remaining at their current speed),
removed obstacle collisions option entirely (since it wasn’t really used, and not core to what the environment is testing),
updated reward so max return is 1.0 (0.5 for reaching destination, and 0.5 from progress) and min return is -1.0 (-1.0 for crashing),
v0: Initial version
References
Adam Lerer and Alexander Peysakhovich. 2019. Learning Existing Social Conventions via Observationally Augmented Self-Play. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. 107–114.
Kevin R. McKee, Joel Z. Leibo, Charlie Beattie, and Richard Everett. 2022. Quantifying the Effects of Environment and Population Diversity in Multi-Agent Reinforcement Learning. Autonomous Agents and Multi-Agent Systems 36, 1 (2022), 1–16