Pursuit Evasion Continuous
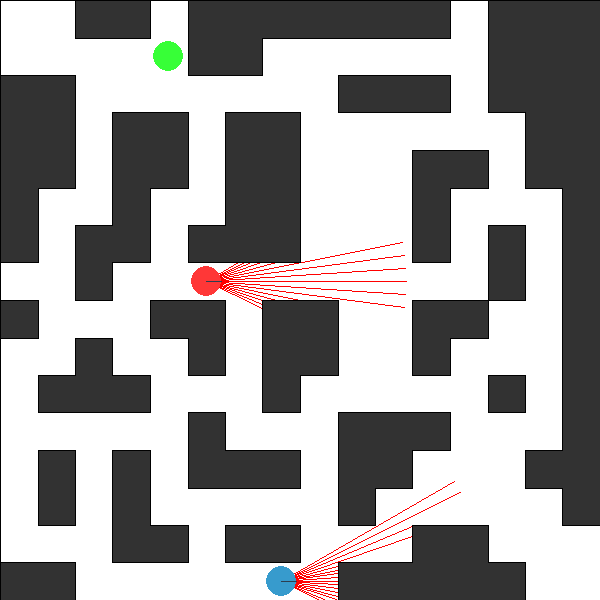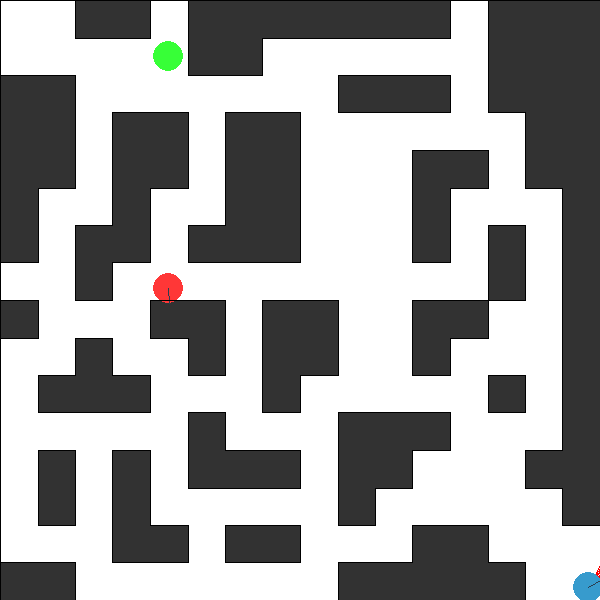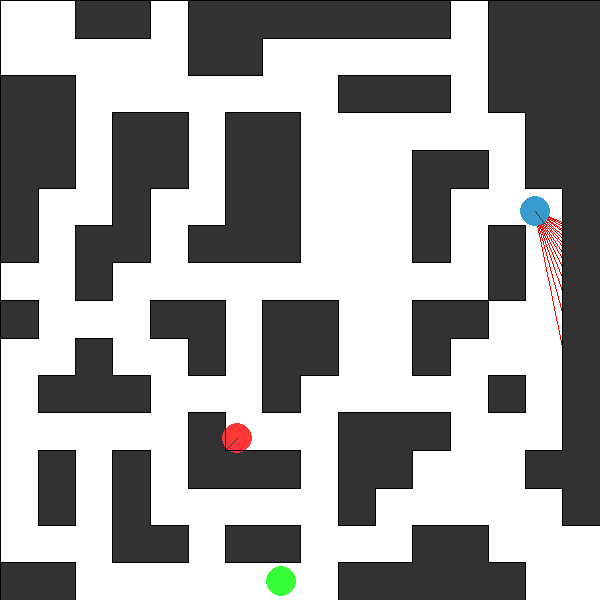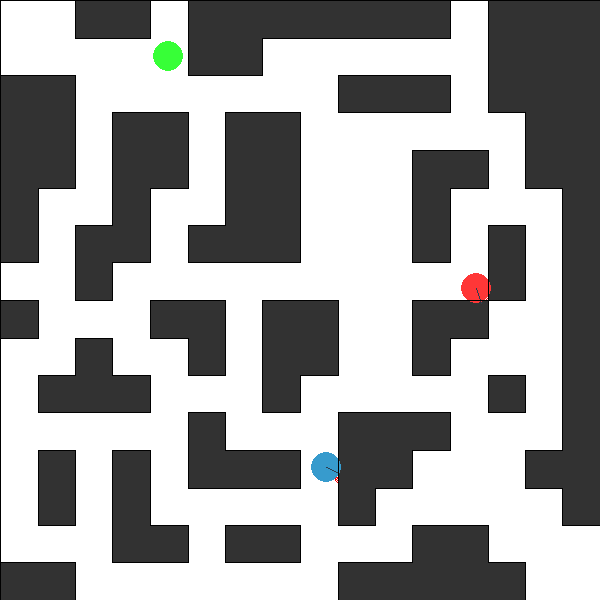
This environment is part of the Continuous environments. Please read that page first for general information.
Possible Agents |
(‘0’, ‘1’) |
Action Spaces |
{‘0’: Box([-0.7853982 0. ], [0.7853982 1. ], (2,), float32), ‘1’: Box([-0.7853982 0. ], [0.7853982 1. ], (2,), float32)} |
Observation Spaces |
{‘0’: Box(0.0, [ 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 1. 16. 16. 16. 16. 16. 16. ], (39,), float32), ‘1’: Box(0.0, [ 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 5.3333335 1. 16. 16. 16. 16. 16. 16. ], (39,), float32)} |
Symmetric |
False |
Import |
|
The Pursuit-Evasion Continuous World Environment.
An adversarial continuous world problem involving two agents: an evader and a pursuer. The evader’s goal is to reach a goal location, on the other side of the world, while the goal of the pursuer is to spot the evader before it reaches it’s goal. The evader is considered caught if it is observed by the pursuer, or occupies the same location. The evader and pursuer have knowledge of each others starting locations, however only the evader has knowledge of it’s goal location. The pursuer only knowns that the evader’s goal location is somewhere on the opposite side of the world to the evaders start location.
This environment requires each agent to reason about the which path the other agent will take through the environment.
Possible Agents
Evader =
"0"Pursuer =
"1"
State Space
Each state is made up of:
the state of the evader
the state of the pursuer
the
(x, y)coordinate of the evader’s start locationthe
(x, y)coordinate of the pursuer’s start locationthe
(x, y)coordinate of the evader’s goalthe minimum distance to it’s goal along the shortest discrete path achieved by the evader in the current episode (this is needed to correctly reward the agent for making progress.)
Both the evader and pursuer state consist of their:
(x, y)coordinateangle/yaw (in radians)
velocity in x and y directions
angular velocity (in radians)
Action Space
Each agent’s actions is made up of two parts. The first action component specifies
the angular velocity in [-pi/4, pi/4], and the second component specifies the
linear velocity in [0, 1].
Observation Space
Each agent observes the local world in a fov radian cone in front of
themselves. This is achieved by a series of n_sensors sensor lines starting
at the agent which extend up to max_obs_distance away from the agent.
For each sensor line the agent observes the closest entity along the line,
specifically if there is a wall or the other agent. Along with the sensor
readings each agent also observes whether they hear the other agent within
a circle with radius ``HEARING_DIST = 4.0around themselves, the(x, y)coordinate of the evader's start location and the(x, y)coordinate of the pursuer's start location. The evader also observes the(x, y)coordinate of their goal location, while the pursuer receives a value of(0, 0` for
this feature.
This table enumerates the first part of the observation space:
Index: start |
Description |
Values |
|---|---|---|
0 |
Wall distance |
[0, d] |
n_sensors |
Other agent distance |
[0, d] |
2 * n_sensors |
Other agent heard |
[0, 1] |
2 * n_sensors + 1 |
Evader start coordinates |
[0, s] |
2 * n_sensors + 3 |
Pursuer start coordinates |
[0, s] |
2 * n_sensors + 5 |
Evader goal coordinates |
[0, s] |
Where d = max_obs_distance and s = world.size
If an entity is not observed by a sensor (i.e. it’s not within max_obs_distance
or is not the closest entity to the observing agent along the line), The distance
reading will be max_obs_distance.
Note, the goal and start coordinate observations do not change during a single episode, but they do change between episodes.
Rewards
The environment is zero-sum with the pursuer receiving the negative of the evader
reward. Additionally, rewards are by default normalized so that returns are bounded
between -1 and 1 (this can be disabled by the normalize_reward parameter).
The evader receives a reward of 1 for reaching it’s goal location and a
reward of -1 if it gets captured. Additionally, the evader receives a small
reward of 0.01 each time it’s minimum distance achieved to it’s goal along the
shortest path decreases for the current episode. This is to make it so the
environment is no longer sparesely rewarded and helps with exploration and learning
(it can be disabled by the use_progress_reward parameter.)
Dynamics
Actions are deterministic and will change the agents direction and velocity in the direction they are facing. The velocity range of an agent is [0, 1]; agent’s cannot move backwards (have negative velocity).
Starting State
At the start of each episode the start location of the evader is selected at random from all possible start locations. The evader’s goal location is then chosen randomly from the set of available goal locations given the evaders start location (in the default maps the goal location is always on the opposite side of the map from a start location). The pursuers start location is similarly chosen from it’s set of possible start locations.
Episode End
An episode ends when either the evader is seen or touched by the pursuer or the
evader reaches it’s goal. By default a max_episode_steps limit of 200 steps is
also set. This may need to be adjusted when using larger worlds (this can be done
by manually specifying a value for max_episode_steps when creating the environment
with posggym.make).
Arguments
world- the world layout to use. This can either be a string specifying one of the supported worlds (see SUPPORTED_WORLDS), or a custom :class:PEWorldobject (default ="16x16").max_obs_distance- the maximum distance from the agent that each agent’s field of vision extends. IfNonethen sets this to 1/3 of world size (default =None).fov- the field of view of the agent in radians. This will determine the angle of the cone in front of the agent which it can see. The FOV will be relative to the angle of the agent (default =pi / 3).n_sensors- the number of sensor lines eminating from the agent within their FOV. The agent will observe atn_sensorsequidistance intervals over[-fov / 2, fov / 2](default =16).normalize_reward- whether to normalize both agents’ rewards to be between-1and1(default = ‘True`)use_progress_reward- whether to reward the evader agent for making progress towards it’s goal. If False the evader will only be rewarded when it reaches it’s goal, making it a sparse reward problem (default = ‘True`).
Available variants
The PursuitEvasionContinuous environment comes with a number of pre-built world
layouts which can be passed as an argument to posggym.make, to create different
worlds.
World name |
World size |
|---|---|
|
8x8 |
|
16x16 |
|
32x32 |
For example to use the PursuitEvasionContinuous environment with the 32x32 world
layout, and episode step limit of 200, and the default values for the other
parameters you would use:
import posggym
env = posggym.make(
'PursuitEvasionContinuous-v0',
max_episode_steps=200,
world="32x32",
)
References
[This Pursuit-Evasion implementation is directly inspired by the problem] Seaman, Iris Rubi, Jan-Willem van de Meent, and David Wingate. 2018. “Nested Reasoning About Autonomous Agents Using Probabilistic Programs.” ArXiv Preprint ArXiv:1812.01569.
Schwartz, Jonathon, Ruijia Zhou, and Hanna Kurniawati. “Online Planning for Interactive-POMDPs using Nested Monte Carlo Tree Search.” In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 8770-8777. IEEE, 2022.